4.1. Content-based classification
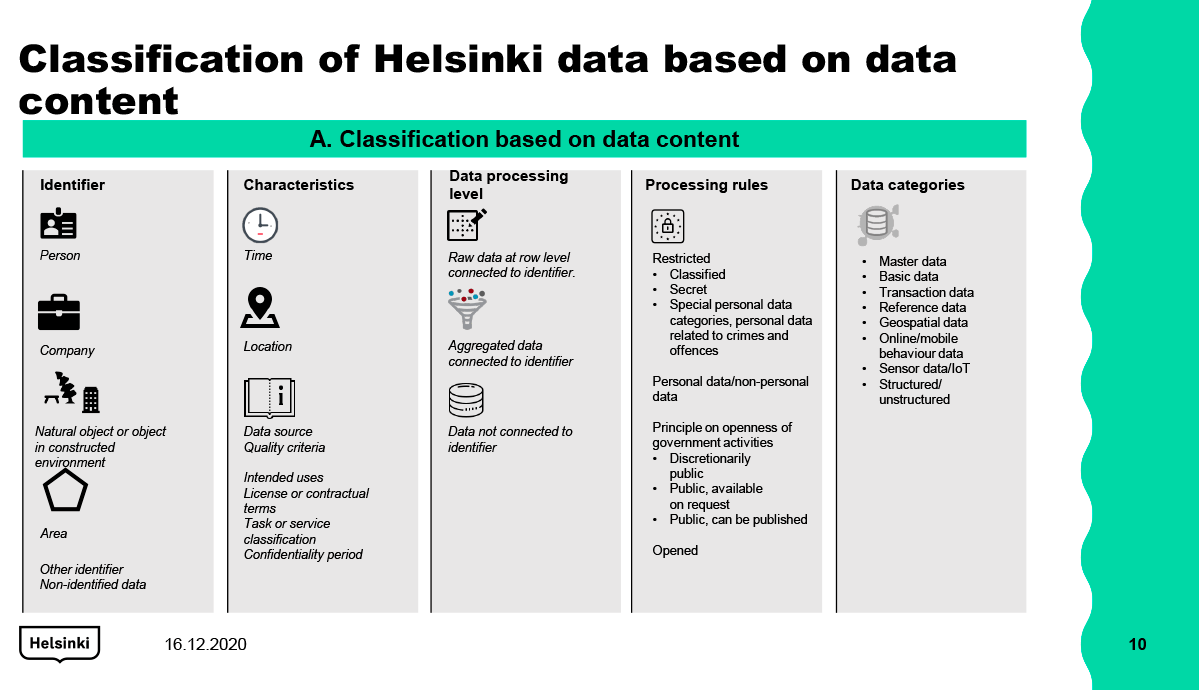
Figure 5. Content-based data classification
|
Identifier |
Defines which identifier level the data is linked to. For personal data, the identifier can be a Helsinki profile identifier, a personal identity code or an e-mail address, for example, but individuals are also identified by devices or cookies. The identifier level can also be a company (such as a business ID), a nature site or a built environment site (site identifier) or an area (such as a postal code area). The identifier can also be a website URL, for example. Data can also not have an identifier (such as statistics). |
|
Attributes |
Information related to the data. Examples include the source, collection time or place or purpose of the data and associated processing rules. In the case of the 3D City model, attributes also include scale and location accuracy. A key part of metadata, useful for the utilisation and lifecycle management of the data. |
|
Data processing level |
Defines the level at which the data is processed. The processing level can be row-level raw data (such as a person’s service history or measuring data produced by a sensor), data not linked to an identifier (such as statistical data), or aggregated data linked to an identifier (such as data linked to a customer detailing how many times they have used cultural services during the year, or area-level statistical data). |
|
Data processing rules |
Describes data from the perspective of processing restrictions: whether the data is personal data, belongs to a special category of personal data, is confidential or security-classified data, or is public or open. See Section 4.3. |
|
Data categories |
Describe different information resources. Different categories have different requirements in terms of data processing. For example, master data requires processes for ensuring the administration and use of common data from a centralised source, whereas online behaviour or sensor data can be stored in a cloud environment to facilitate the processing of large data masses. Datasets belonging to the same category are primarily subject to the same usage rules, through the individual characteristics of the division and other classification criteria can cause variation. Data can also be classified based on themes, see for example hri.fi, where data is categorised according to a JHS Recommendation (JHS183). |